First impressions matter
Cold starts have long been the Achilles’ heel of traditional serverless. It’s not just the delay itself, but when the delay happens. Cold starts happen when someone new discovers your app, when traffic is just starting to pick up, or during those critical first interactions that shape whether people stick around or convert.
Traditional serverless platforms shut down inactive instances after a few minutes to save costs. But then when traffic returns, users are met with slow load times while new instances spin up. This is where developers would normally have to make a choice. Save money at the expense of unpredictable performance, or pay for always-on servers that increase costs and slow down scalability.
But what if you didn't have to choose? That’s why we built a better way.
Powered by Fluid compute, Vercel delivers zero cold starts for 99.37% of all requests. Fewer than one request in a hundred will ever experience a cold start. If they do happen, they are faster and shorter-lived than on a traditional serverless platform.
Through a combination of platform-level optimizations, we've made cold starts a solved problem in practice. What follows is how that’s possible and why it works at every scale.
Link to headingWhat a cold start is and why it matters
A cold start happens when a serverless function instance must initialize from scratch to handle a request. The platform allocates compute resources, loads your application code, initializes the runtime environment, and establishes network connections. This process can take up to several seconds.
For users, this translates to blank screens, loading spinners, or unresponsive interfaces during what should be instant interactions.
The unpredictability makes it hard to debug and explain to stakeholders. You can't easily reproduce them in development, since your local environment stays warm, and they're difficult to monitor because they happen sporadically.
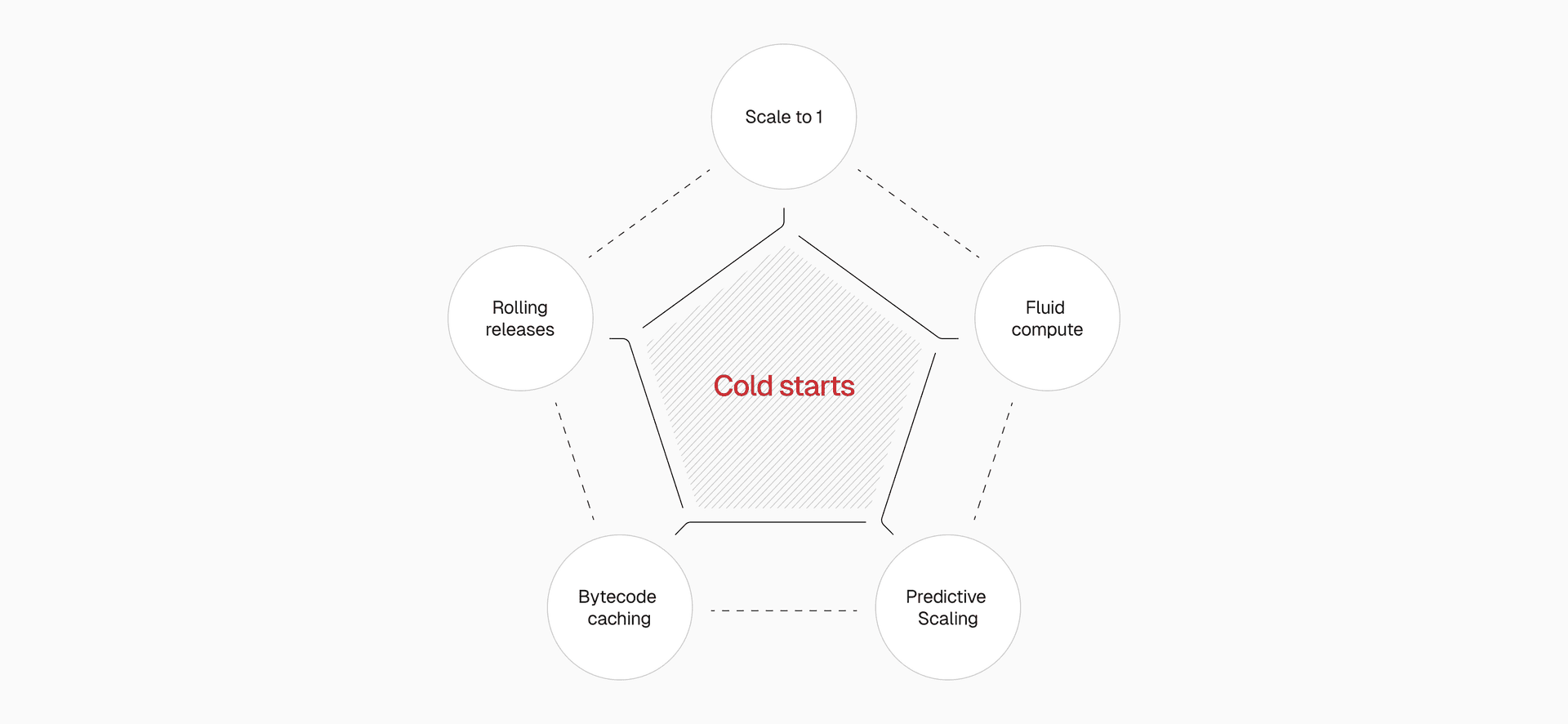
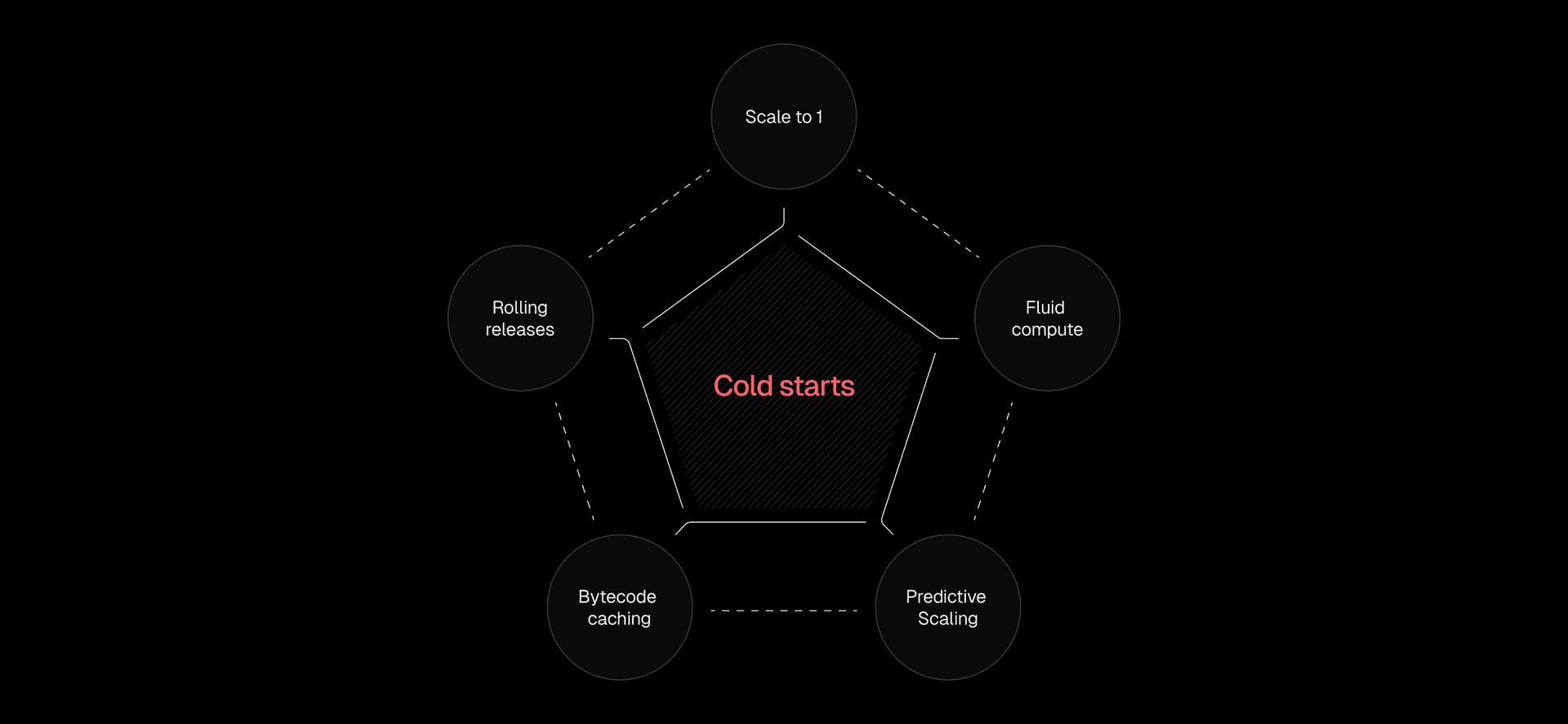
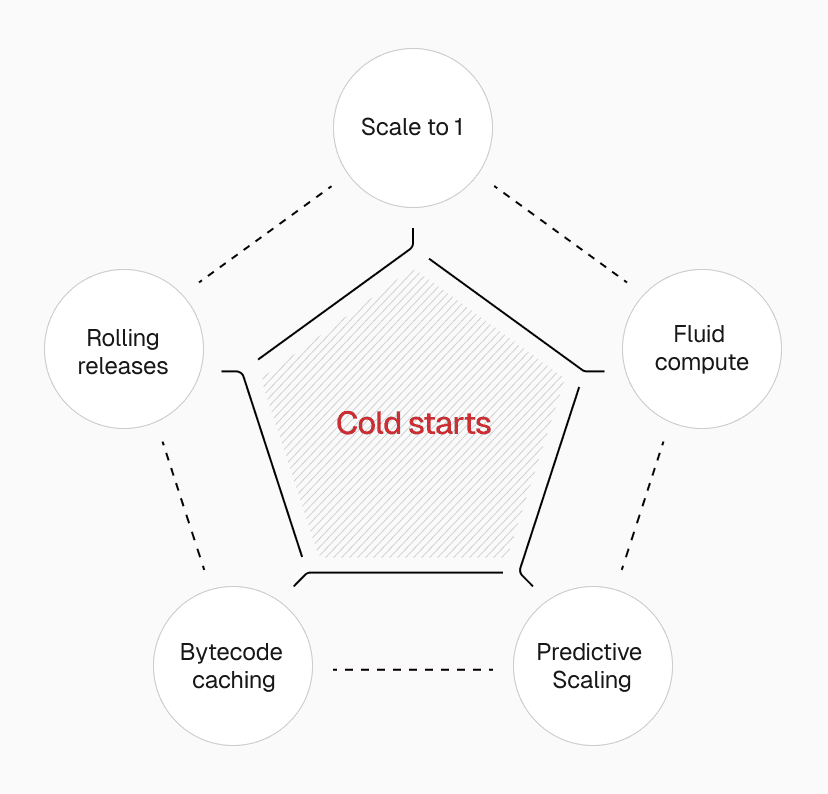
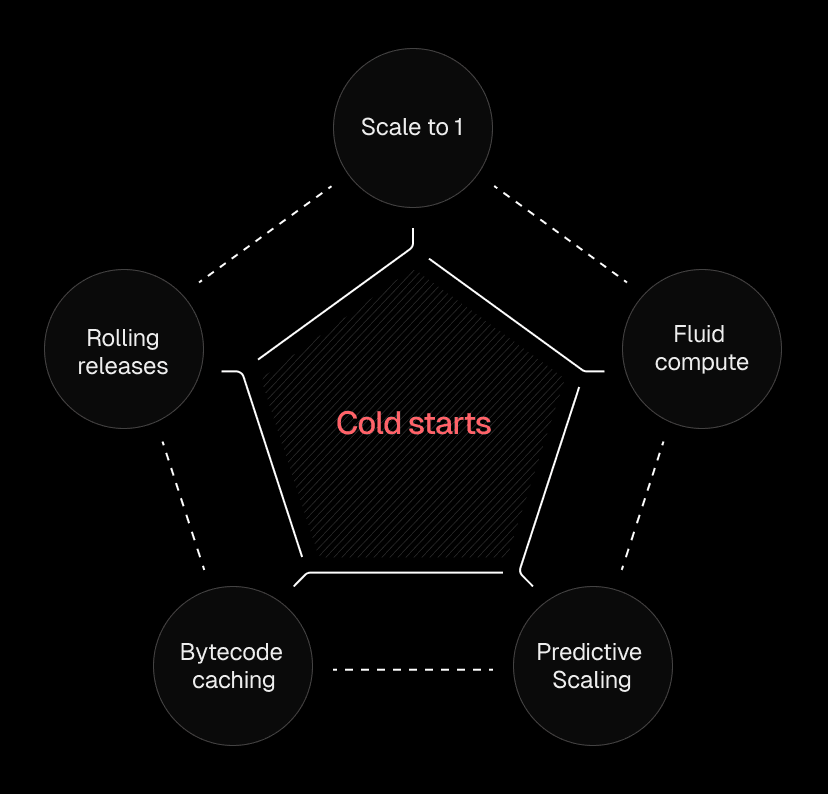
Link to headingHow Vercel prevents cold starts: The complete solution stack
Our approach tackles cold starts from five angles:
Prevention: Scale to one keeps instances warm before they're needed
Frequency reduction: Fluid compute reuses existing instances for multiple requests
Anticipation: Predictive scaling warms instances ahead of demand
Impact reduction: Bytecode caching makes unavoidable cold starts faster
Release management: Rolling releases prevent mass cold starts during deployments
Each layer compounds the others. The result is cold starts becoming a non-issue at any scale.
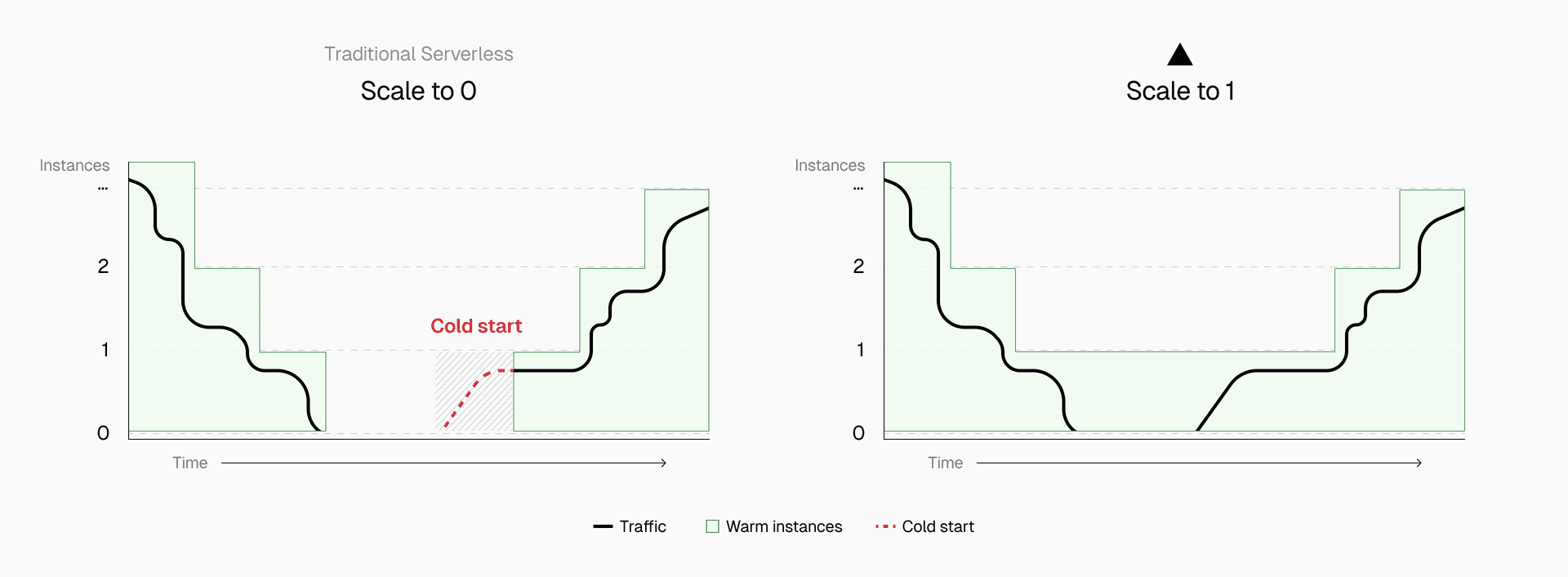
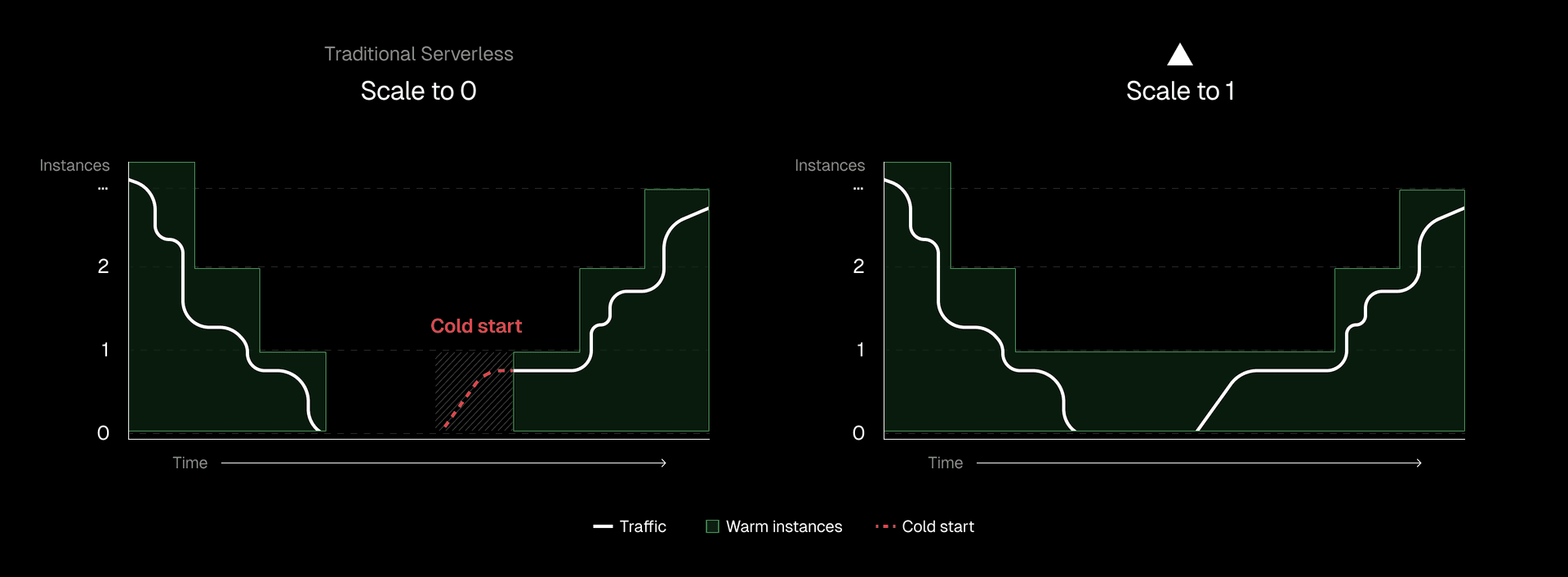
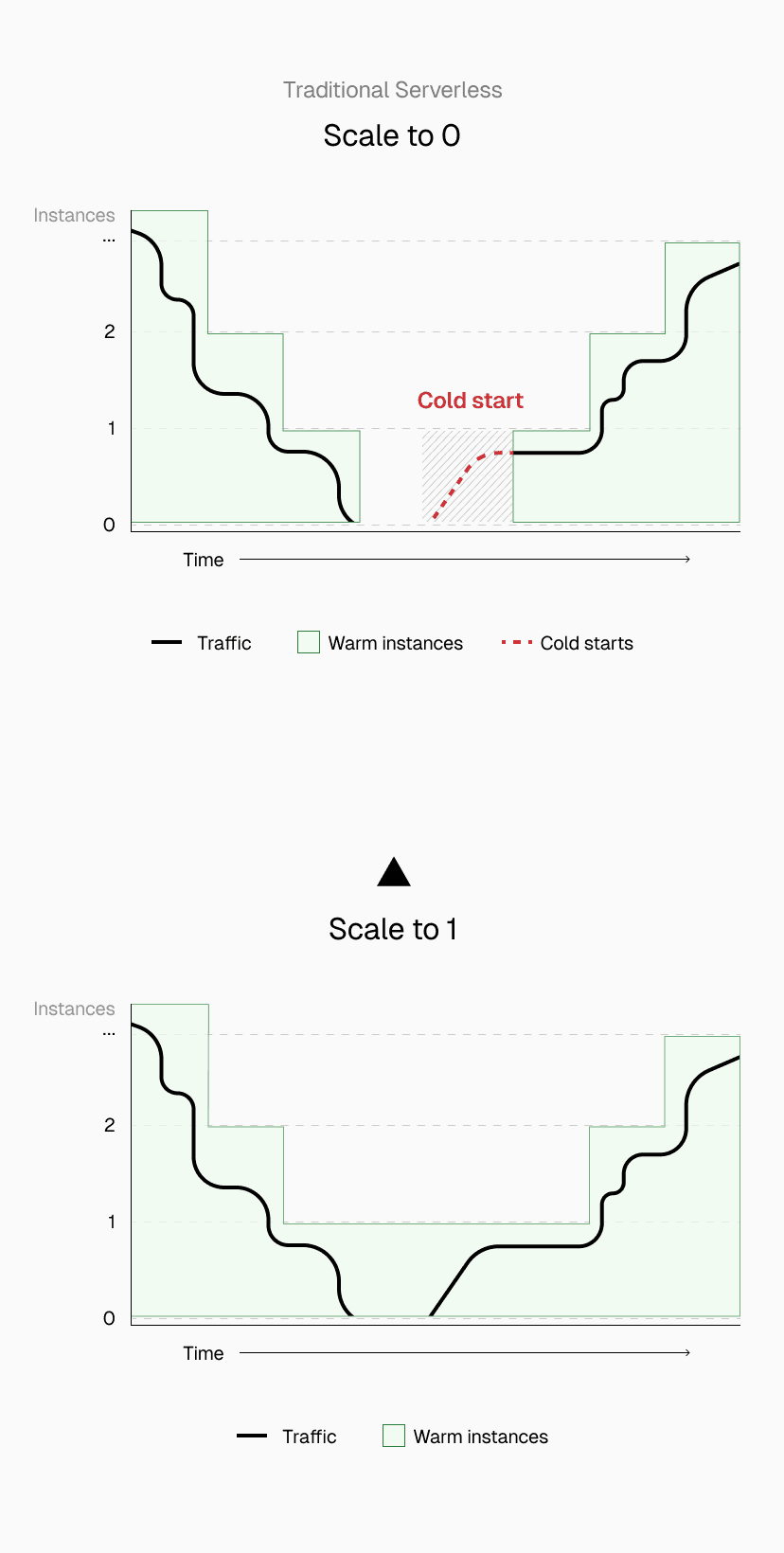
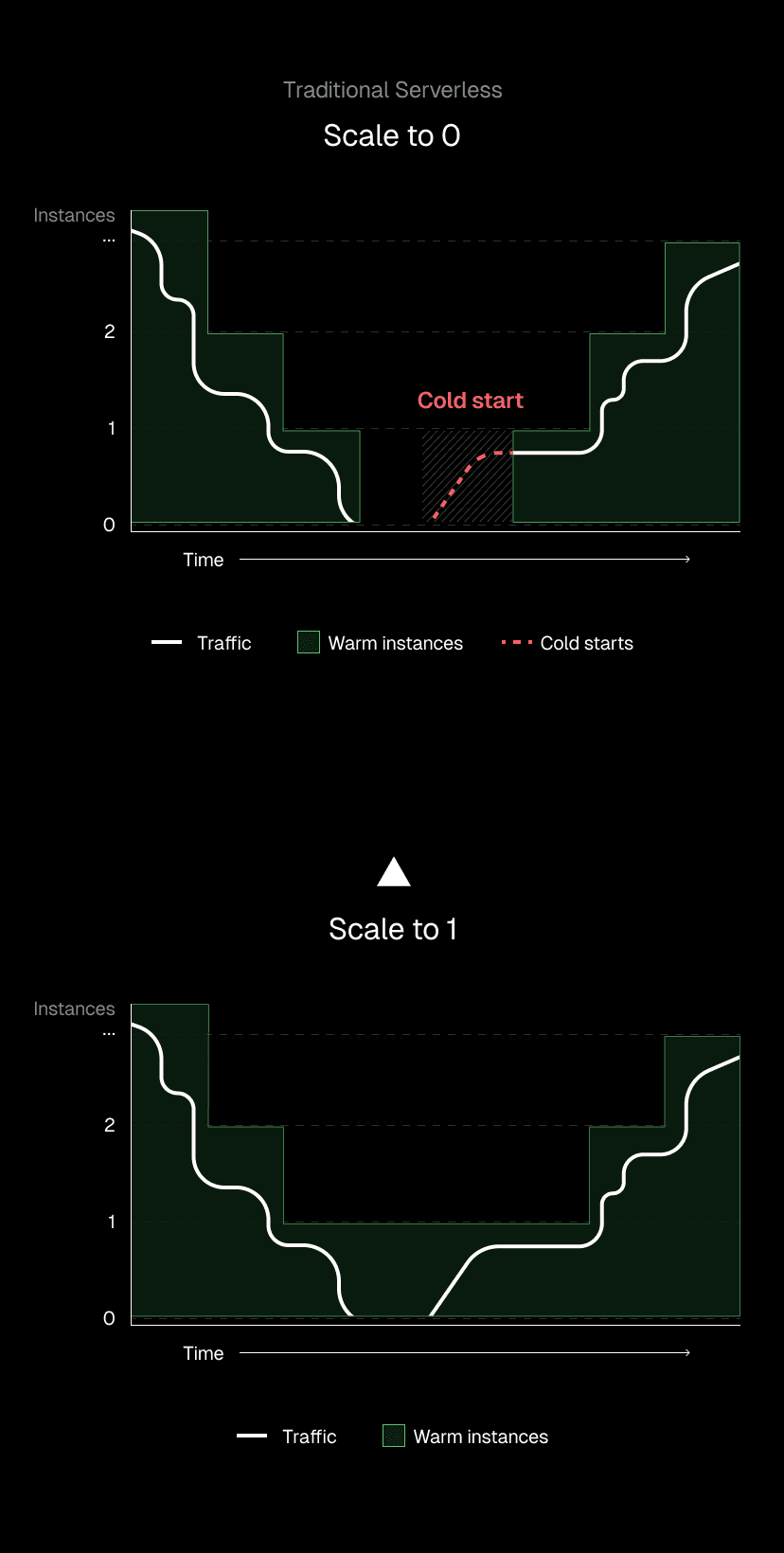
Link to headingScale to one: Eliminating first visitor cold starts
Most serverless platforms scale to zero when idle. Resources that have not received traffic for a few minutes are shut down to improve efficiency. On Vercel, production deployments on Pro and Enterprise plans work differently.
Link to headingHow it works and architecture fit
We always keep at least one function instance running. Instead of scaling to zero, we scale to one. This works automatically for qualifying deployments; there is nothing you need to configure or enable.
Pre-warming prevents a third of potential cold starts. It applies to single-region functions, middlewares, and multi-region functions, providing the foundation that other optimizations build upon.
Link to headingReal-world scenarios
If your app receives very little traffic, scaling to zero would mean almost all initial interactions are cold starts. This produces a poor experience when performance matters most.
Imagine a stealth startup with 20 trusted testers. Each tester's session lasts about five minutes. Testers access the app at random times, often leaving hours between visits. On a traditional serverless platform, each tester experiences a cold start at the most important moment: their first impression of your product.
With scale to one, when a user visits your app, even if no one else has been around in a while, they experience a quick response, from a warm function.
The same problem happens at the enterprise scale with preview deployments. You build a new feature, deploy it to a preview URL, and share it with stakeholders for review. On traditional platforms, if the CEO clicks that preview link hours later, they wait 3-4 seconds for the page to load while the function cold starts. They don't know it's a cold start. They just know your feature feels slow.
For teams on Enterprise plans, scale to one also applies to the most recent deployment of any branch URL for up to three days. That means when executives or other collaborators review feature branches, even at midnight or over the weekend, the experience is instant and responsive. No awkward delays during the demos that matter most.
Link to headingCoverage and conditions
Scale to one applies automatically under these conditions:
Pro and Enterprise plans: current production deployment (warm if invoked in the last 14 days)
Enterprise plans: most recent branch deployment (kept warm up to three days)
There’s no additional cost: you only pay when your app receives usage, unlike dedicated servers that run 24/7.
Link to headingFluid compute: Reuse what's warm
Fluid compute rethinks the traditional serverless model. Instead of spinning up one instance for every request, each function instance can serve many requests at the same time. In practice, functions behave more like lightweight servers, capable of handling concurrent traffic without requests interfering with one another or limiting scalability.


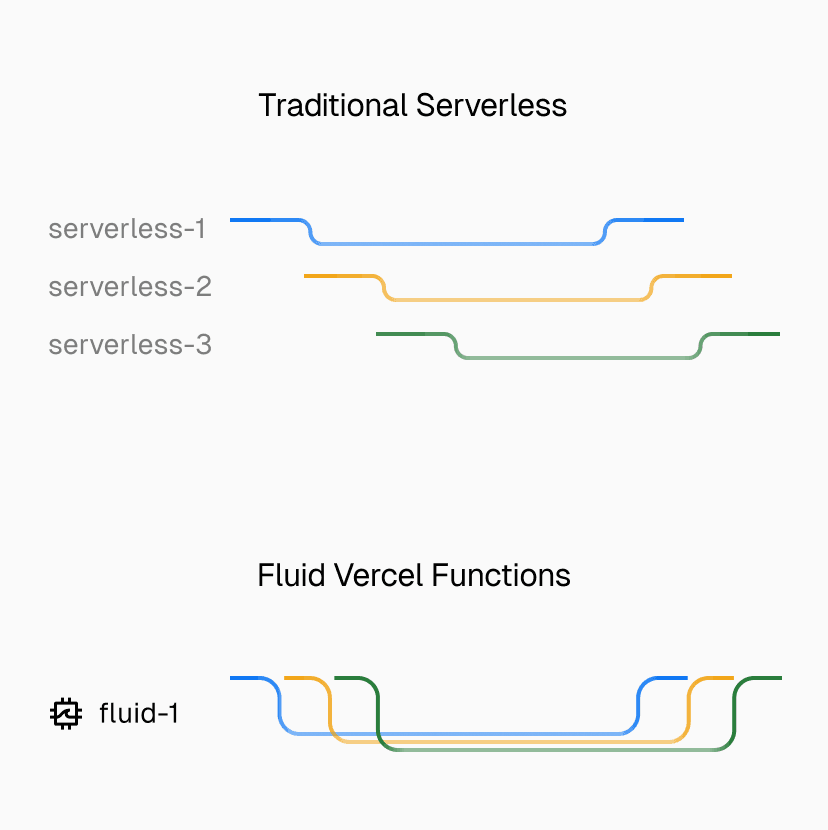

Link to headingHow Fluid compute eliminates cold starts
With traditional serverless, a burst of 100 requests might mean 100 new instances, each with the risk of a cold start. Even with predictive scaling, sudden traffic spikes out of nowhere leave no time to pre-warm, so users still hit delays. With Fluid, those same 100 requests might be served by only a handful of already-warm instances. Fluid routes new requests to existing capacity first, only provisioning new instances when absolutely necessary.
Link to headingPerformance and efficiency gains
Fewer total instances created means far fewer opportunities for cold starts. In production, single instances regularly handle dozens of requests concurrently, with peaks above 250 concurrent requests per instance. Most instances handle at least 3 concurrent requests at a time, with many processing 11 or more concurrent requests simultaneously.
Functions waiting on AI or database responses can process additional requests simultaneously. With Active CPU pricing, you only pay for CPU when code is actively executing, not during those idle periods. By reusing what's already warm, Fluid compute turns cold starts into a rare edge case.
Link to headingPredictive scaling: Warming ahead of demand
Predictive scaling reduces cold starts by preparing instances before traffic arrives. The system observes traffic patterns and allocates capacity ahead of time, so functions are already warm when requests arrive. This avoids the delays of reactive scaling, where new instances are created only after load has increased.
It is particularly effective for traffic that follows regular patterns, such as daily usage cycles or known event times. By pre-warming in advance, requests during those periods are served without interruption, and developers do not need to configure or schedule scaling rules.
Link to headingBytecode caching: Start faster when you must
When cold starts do occur, bytecode caching makes them significantly faster. JavaScript must be parsed and compiled into bytecode before execution. This compilation step is consistently one of the slowest parts of cold starts.
Link to headingHow bytecode caching works
Bytecode caching stores already-compiled bytecode after the first execution. Subsequent cold starts reuse the cached bytecode, removing the compilation penalty entirely.
Our implementation is unique among serverless platforms. We overcome ephemeral file system limitations by intelligently merging bytecode chunks from different routes and lazy-loaded modules. As traffic hits routes like /home and /blog, separate caches merge. The optimization improves as more of your application gets used.
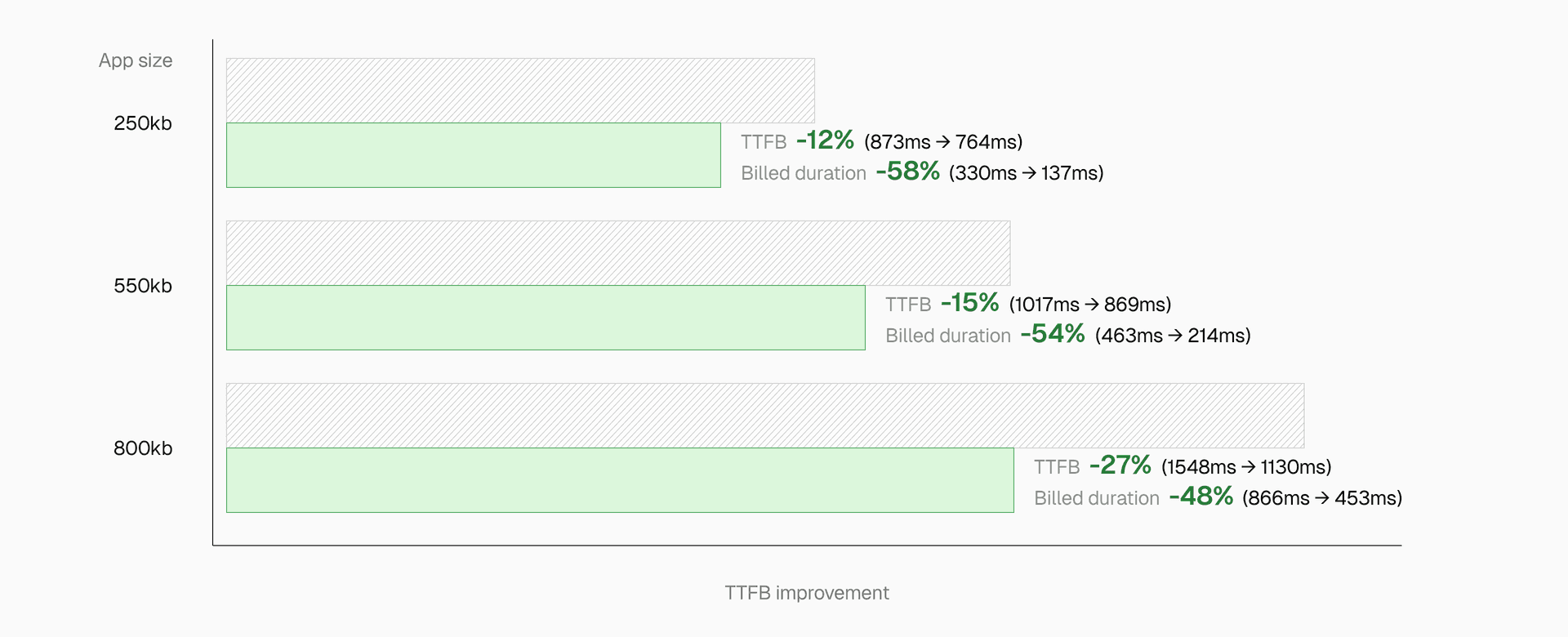
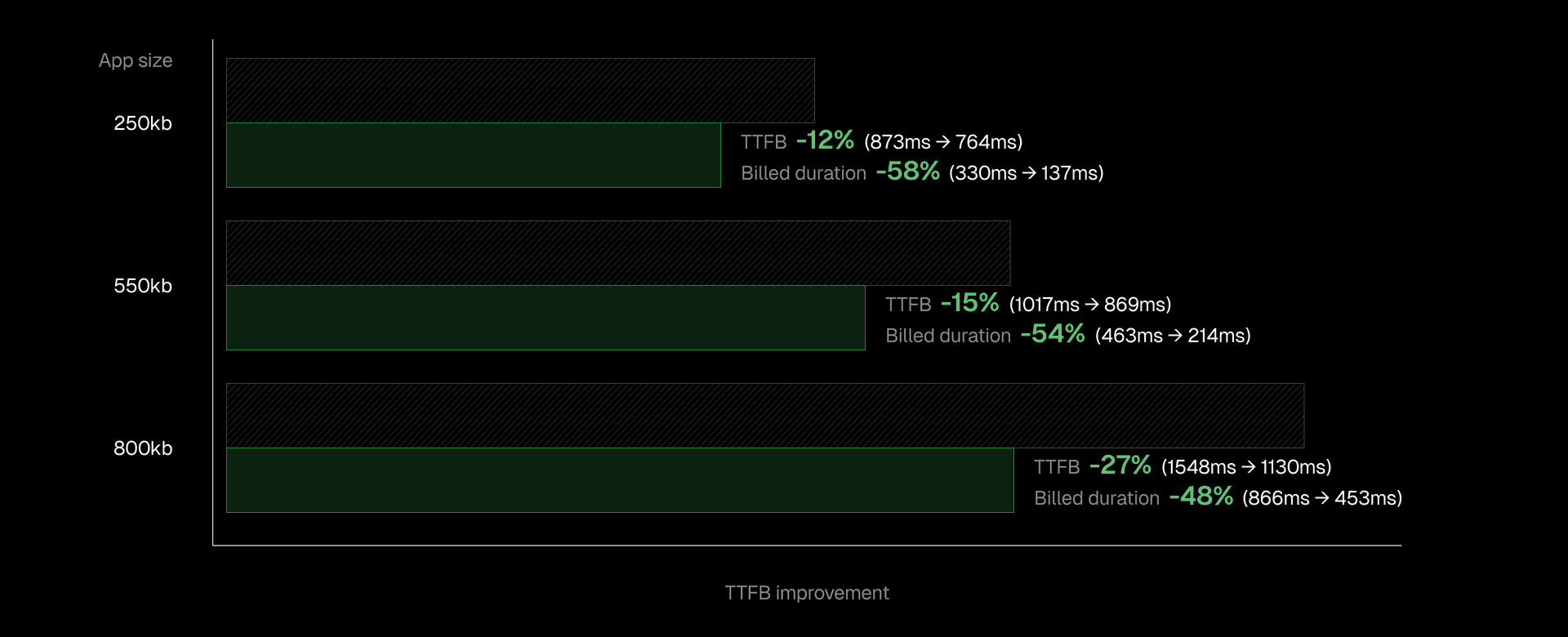
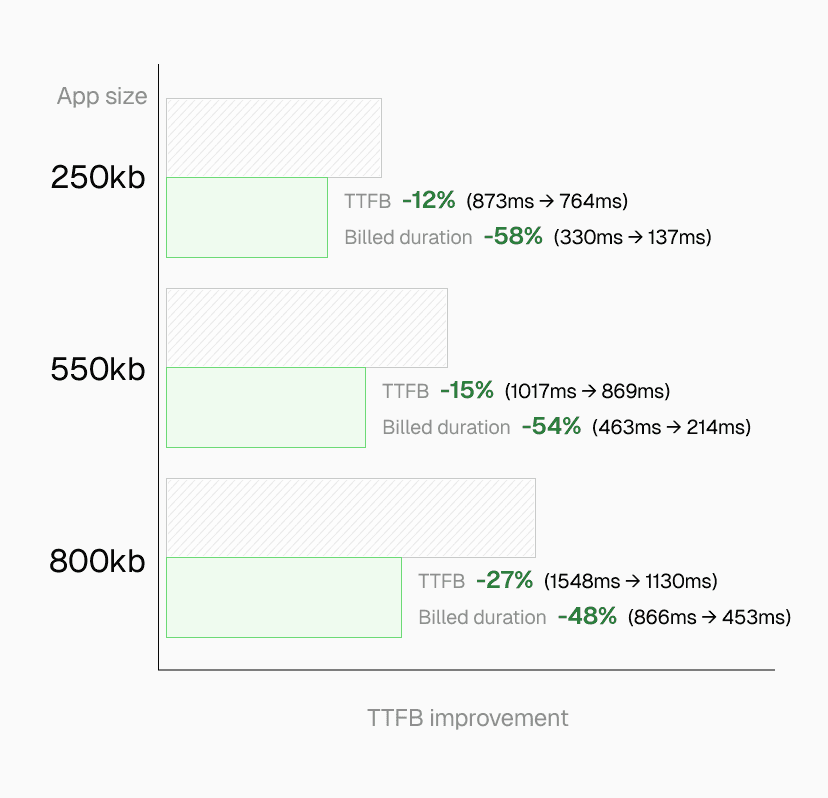
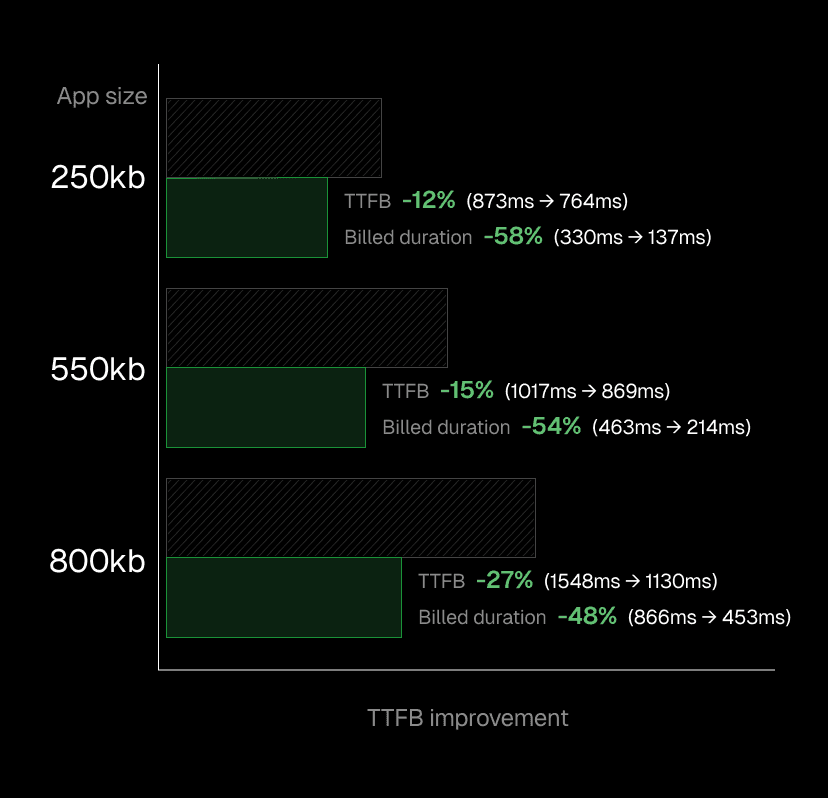
Link to headingPerformance improvements by application size
Real-world tests with Next.js applications show substantial improvements:
Link to headingRolling releases: Preventing deployment-induced cold starts
Traditional deployments create a source of cold starts that exists completely outside normal traffic patterns that other optimizations can't prevent. Even with perfect traffic-based optimizations, when you deploy to production, 100% of traffic suddenly needs new instances. Every user hits a cold start simultaneously.
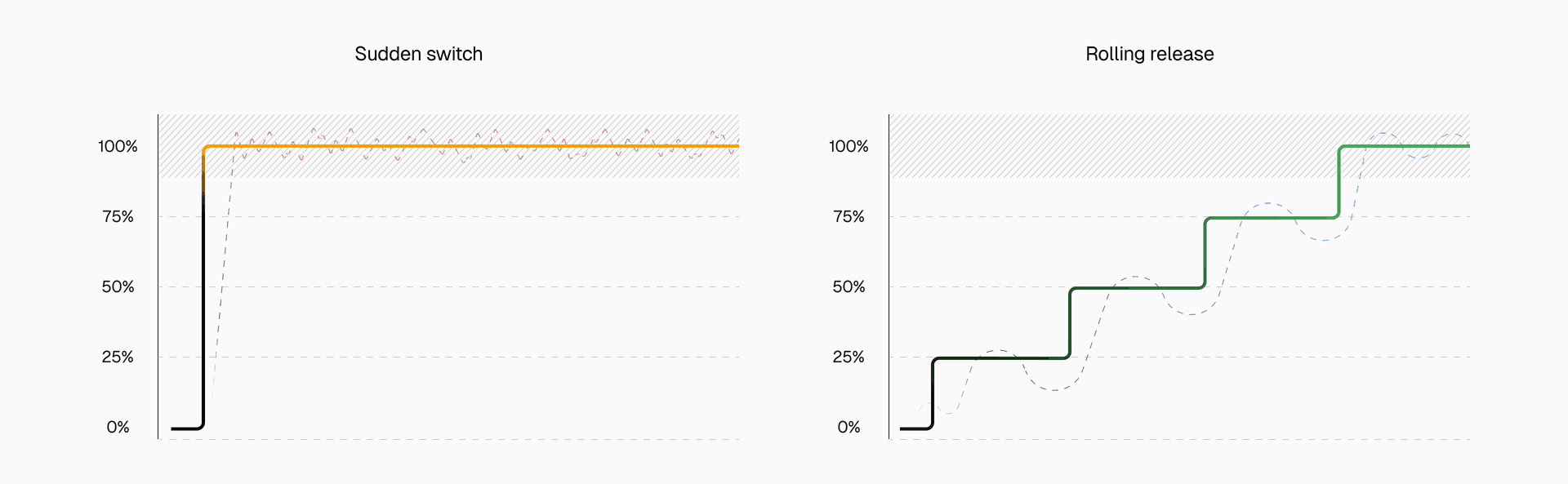
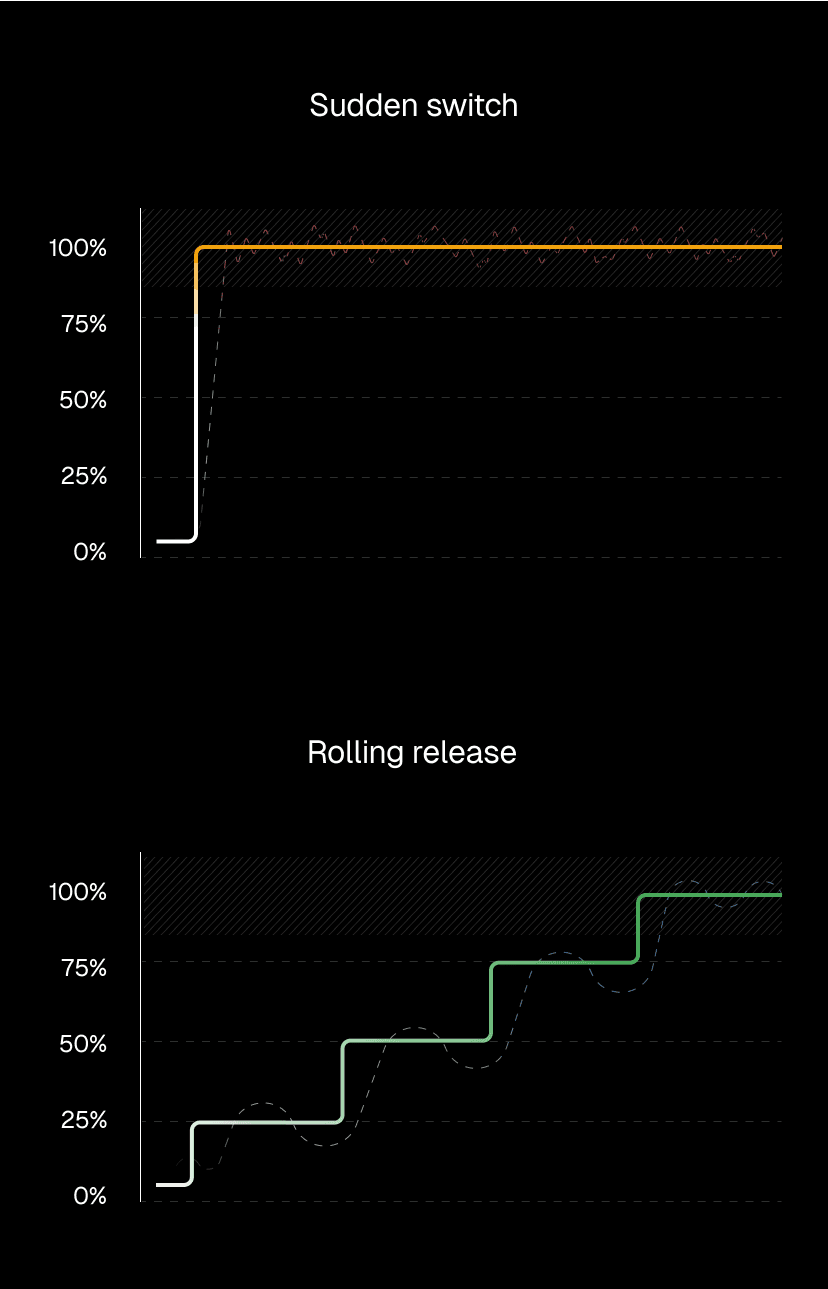
Link to headingHow rolling releases prevent deployment spikes
Rolling releases gradually shift traffic to new deployments instead of switching everything at once. This gradual approach gives Fluid compute time to intelligently provision new instances as demand grows.
When a small percentage of traffic first hits the new deployment, Fluid compute routes requests to already-warm instances and begins pre-warming additional ones. As more traffic shifts over, concurrency and predictive scaling work together to expand capacity ahead of demand. By the time the rollout completes, the new deployment has a full set of warm instances ready to handle 100% of traffic with no cold start penalty.
This transforms deployment from a sudden cold start crisis into a managed scaling event. Instead of every user hitting a cold start when the deployment switches, the infrastructure scales smoothly alongside the traffic migration.
Link to headingCold starts solved at every scale
Cold starts used to be the unavoidable cost of serverless. On Vercel, they’re solved in practice.
Through scale to one, Fluid compute, predictive scaling, bytecode caching, and rolling releases, cold starts are prevented, reduced, or accelerated until they’re no longer a meaningful factor in production. At every scale, from a startup’s first users to global enterprise traffic, applications remain warm and responsive.
Developers don’t need to choose between efficiency and performance anymore. First impressions stay fast, serverless delivers on its promise without trade-offs.
Enable Fluid compute for your deployments
Stop worrying about cold starts and ensure your first impressions are always fast.
Get started