AI Gateway is a Node.js service for connecting to hundreds of AI models through a single interface. It processes billions of tokens per day. The secret behind that scale is Fluid.
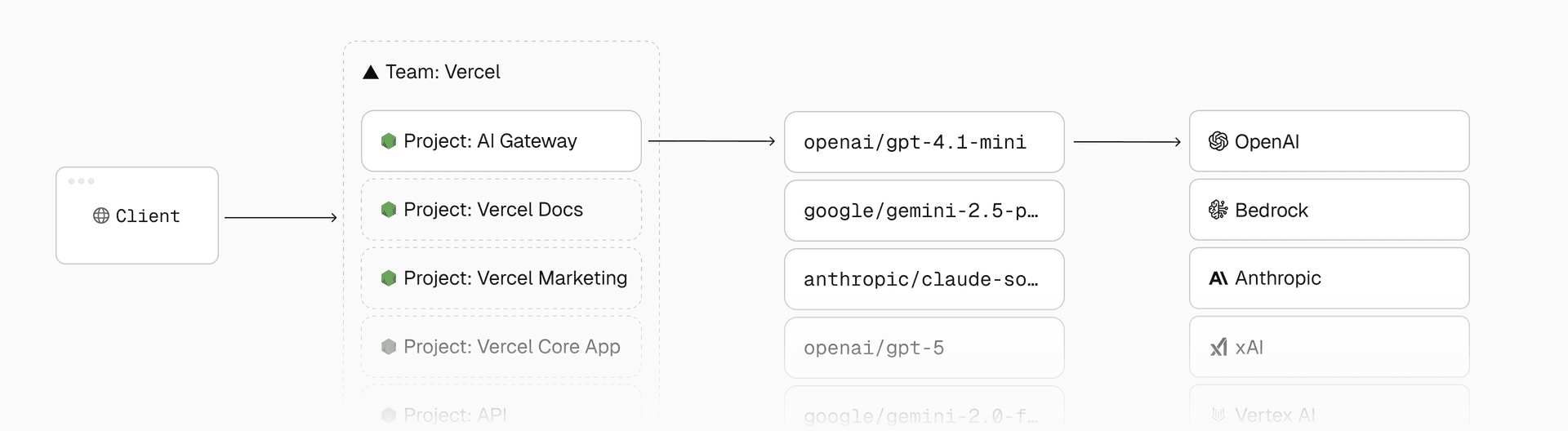
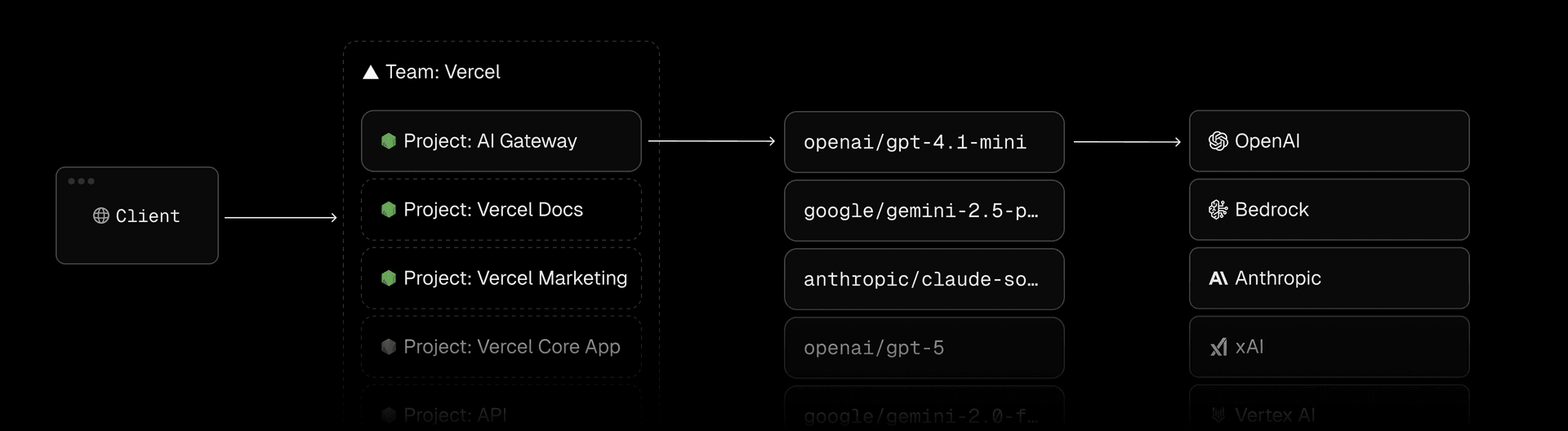
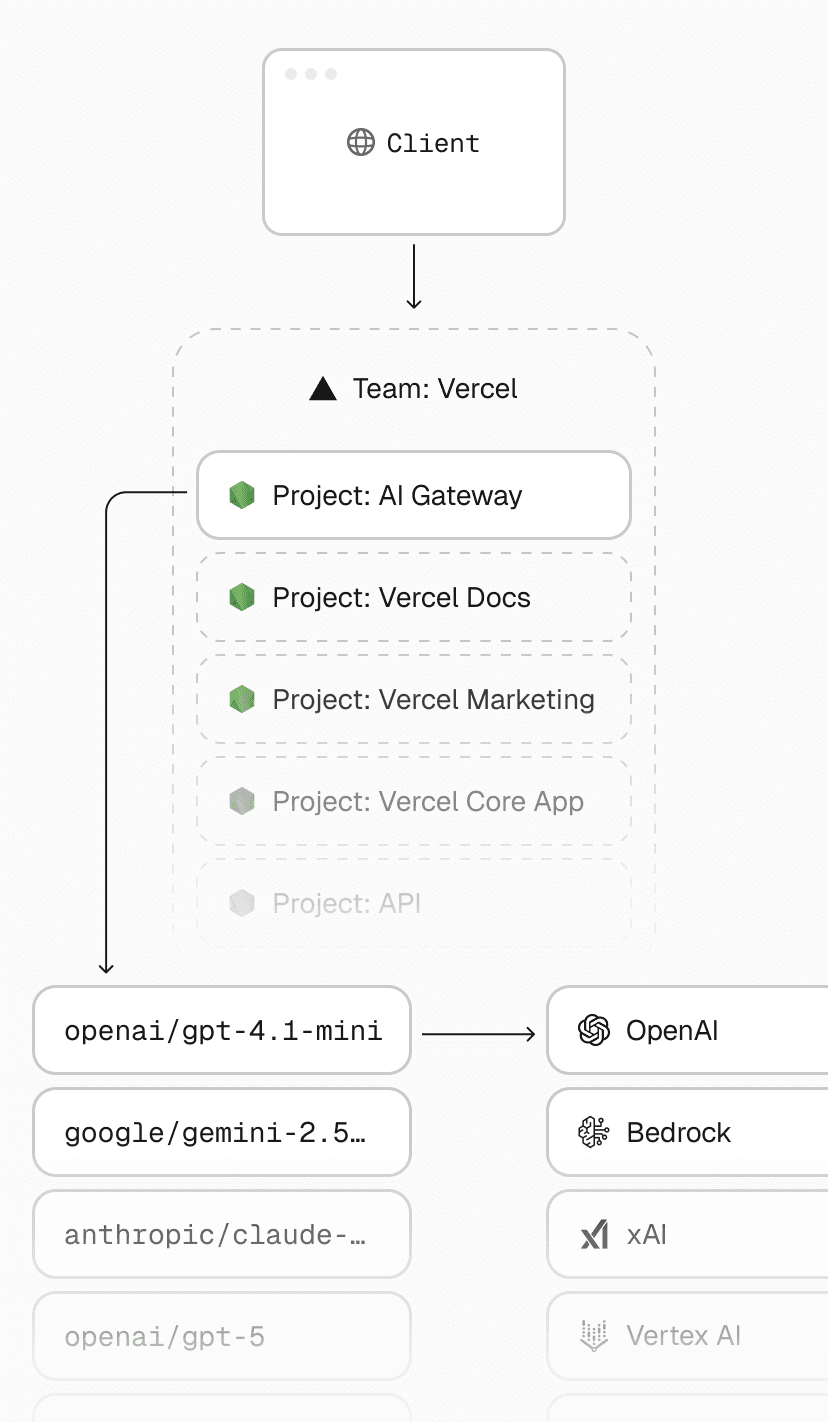
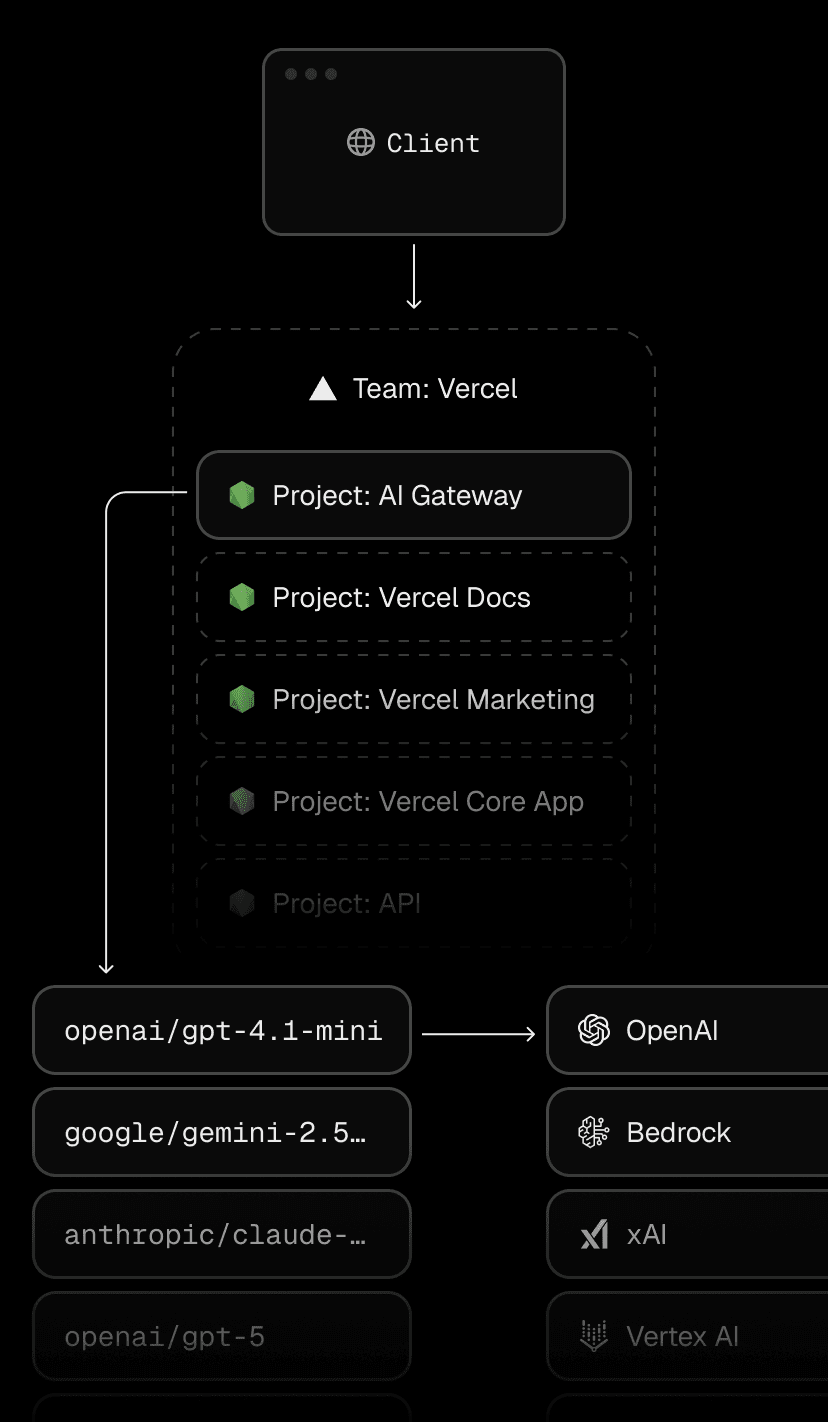
When we announced its general availability, we highlighted how AI Gateway scales efficiently, routes requests securely, and simplifies connecting to multiple AI providers.
We looked at data from the first month of availability. AI Gateway handled roughly 16,000 total runtime hours, but only 1,200 of those hours involved actual CPU work (processing requests, routing logic, streaming responses). The remaining 14,800 hours were spent waiting for AI providers to respond.
Traditional serverless platforms bill you for wall clock time. Every millisecond your function is alive, you pay. With Fluid and Active CPU Pricing, you only pay CPU rates when the CPU is actually running. The rest of the time (when AI Gateway is waiting on OpenAI or Anthropic) you pay a lower memory-only rate. For AI Gateway, that means paying CPU rates for less than 8% of runtime instead of 100%.
By pairing AI Gateway's model abstraction with Fluid's fast, cost-efficient infrastructure, Vercel removes the hardest parts of building AI features. Teams ship faster without worrying about provider plumbing or underlying compute.
Link to headingHow we build Vercel with Vercel
At a high level, AI Gateway is a Node.js app deployed on Vercel using Next.js, though you could build something similar with any backend framework that serves REST APIs.
Despite this straightforward architecture, AI Gateway handles traffic at global scale with extremely low latency. The application runs across the Vercel distributed infrastructure in multiple AWS regions, using the same premium networking, global regions, and compute model available to every Vercel customer.
When a user connects to AI Gateway from outside Vercel, their requests take an accelerated path into our network. For users deploying within AWS, the connection is already local, giving them consistently low latency through in-cloud routing.
Within the product, AI Gateway is just a standard Vercel project without any special infrastructure or privileged access. The application uses the same framework-defined infrastructure, zero-config deployment, observability, and security available to you.
Link to headingUnder the hood: Global delivery network
When a request enters AI Gateway, the request is first received by the Vercel global delivery network, a globally distributed system that combines Anycast routing, Points of Presence (PoPs), and private backbone connectivity to minimize latency.
The network continuously evaluates the health and congestion of each endpoint, routing requests to the optimal PoP based on proximity and live performance telemetry. From there, traffic is handed off to the nearest compute-capable region, where the request runs within the same global infrastructure that powers every Vercel deployment.
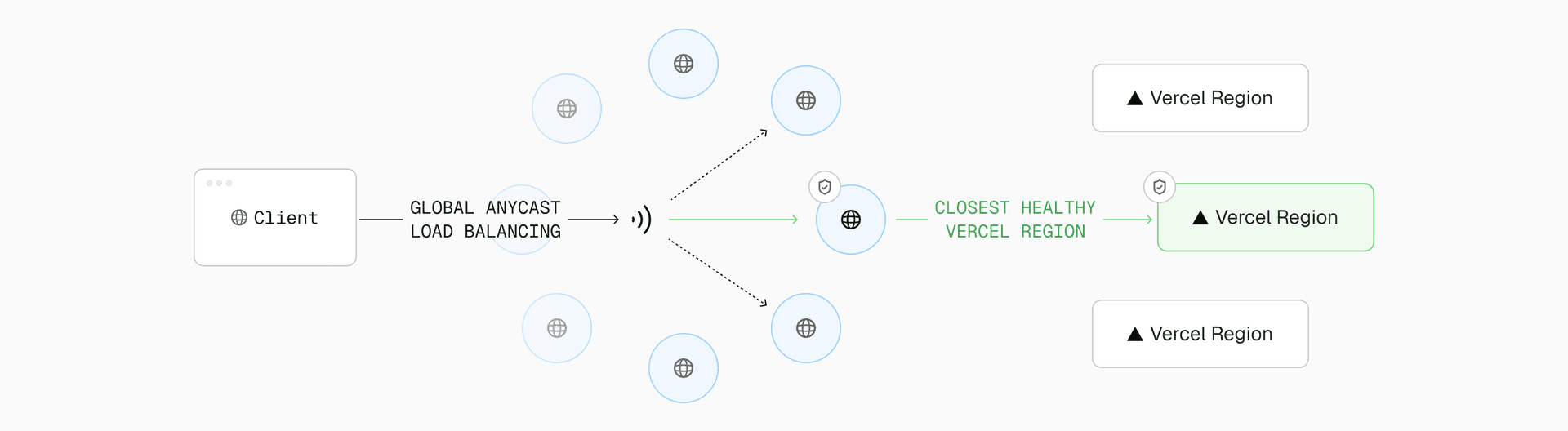
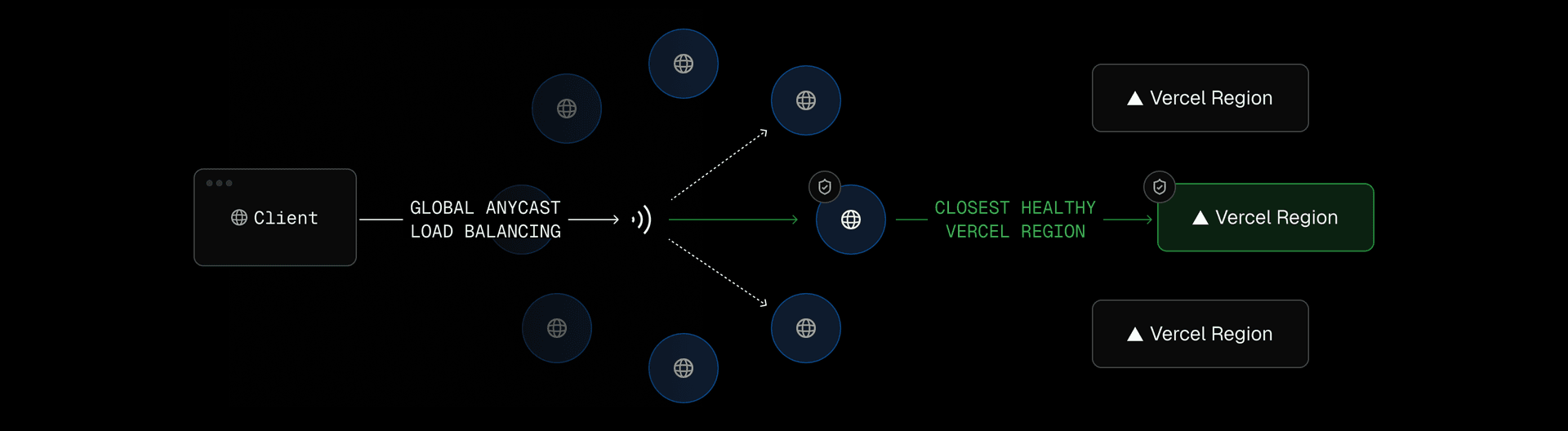
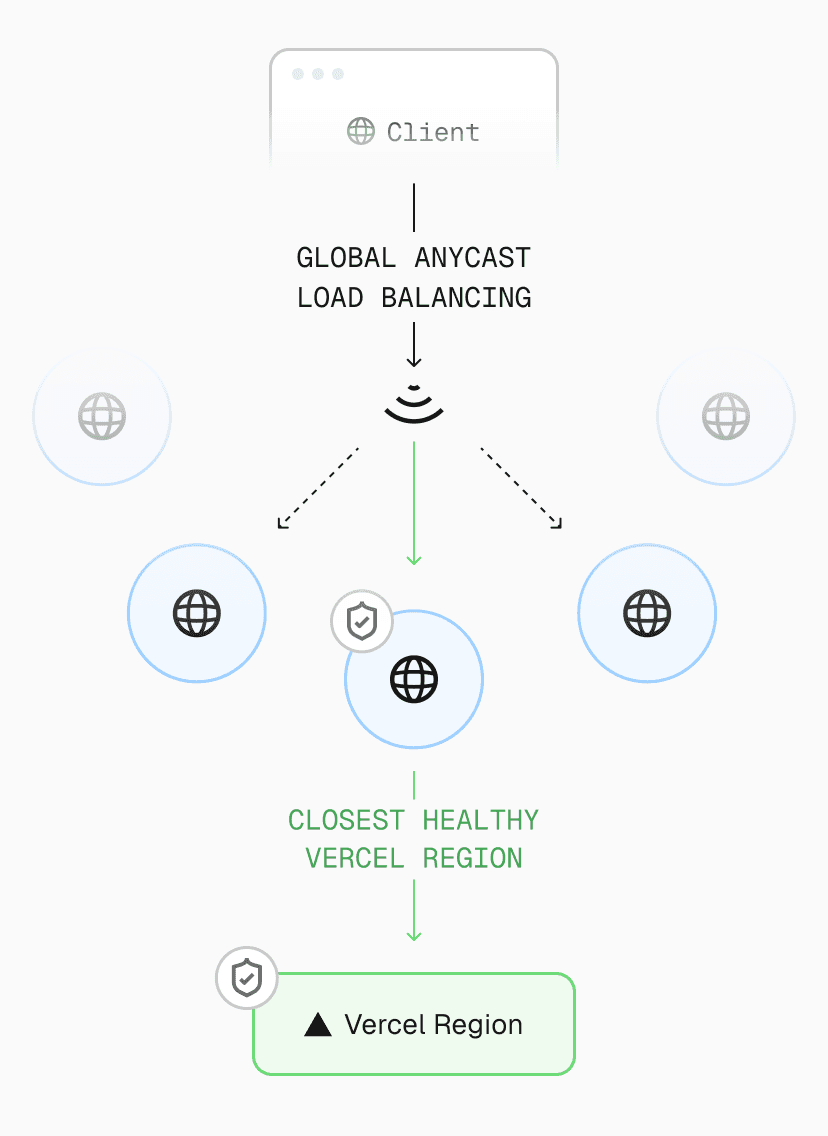
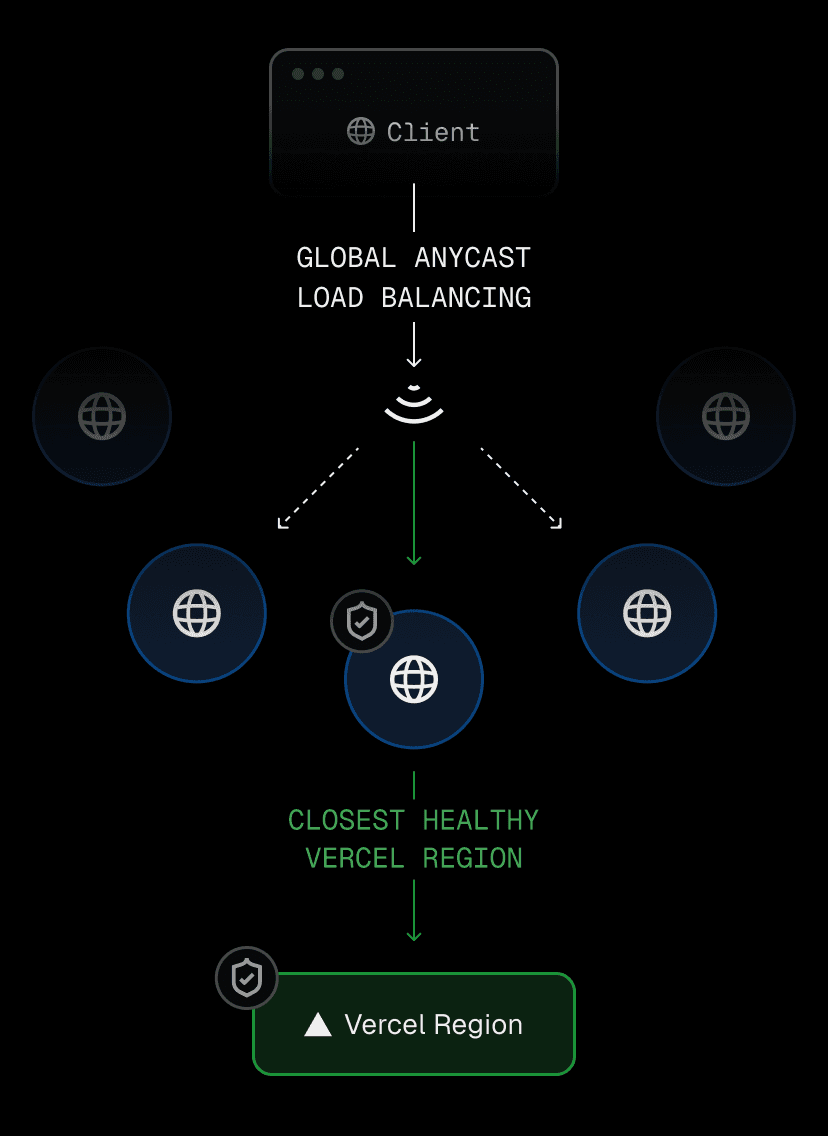
The delivery network ensures high-throughput, low-latency movement of data between users, network region locations, and AI providers. Each hop, from client ingress to provider response, remains within Vercel managed boundaries, avoiding unpredictable public internet routes.
This architecture delivers consistent performance globally, keeping round-trip times to single-digit milliseconds for most customers while maintaining full visibility through edge request metrics.
Once routed, the request reaches AI Gateway's application layer and executes within a Vercel Function running on Fluid compute. The function authenticates using OIDC tokens for Vercel-hosted apps or API keys for external integrations. The function verifies quotas through in-region Redis and prepares the payload for the target AI provider. After forwarding the request, the function streams responses back through the same low-latency network path.
import { generateText } from 'ai';
const { text } = await generateText({ model: 'anthropic/claude-sonnet-4', prompt: 'Explain how request routing works',});Example using AI Gateway with the AI SDK
Link to headingUnder the hood: Powered by Fluid compute
AI Gateway runs on Fluid compute, our next-generation runtime for highly concurrent, network-bound workloads. Fluid behaves like a dynamic, short-lived server, retaining the elasticity and deployment model of serverless while reusing underlying cloud resources across invocations for server-like efficiency.
Traditional serverless models require a separate instance for every invocation. Even if pre-warmed, each traditional serverless instance starts with no memory or state.
Fluid changes this by not just reusing instances across invocations when they're done running, but while they're running as well, through in-function concurrency. This allows in-memory data, open sockets, and runtime caches to persist throughout an instance's lifecycle. When one invocation pauses to wait for a provider's response, another can execute immediately within the same instance.
This concurrency model keeps CPU utilization high and costs low. With Active CPU Pricing, you only pay for the milliseconds when your code is actively running.
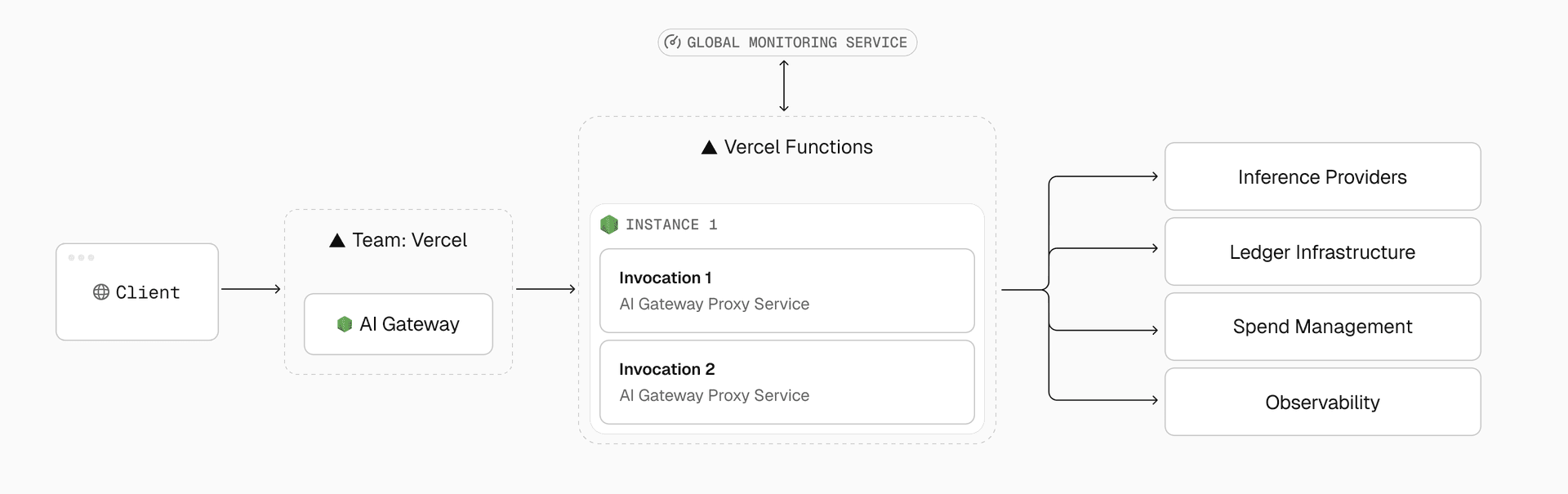
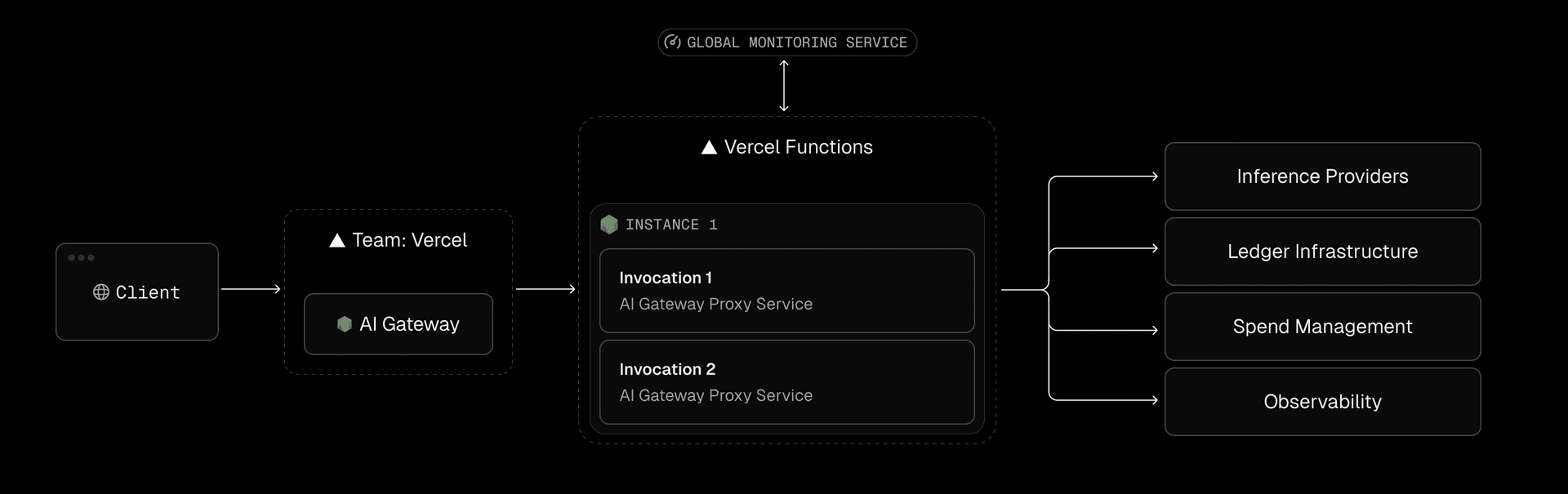
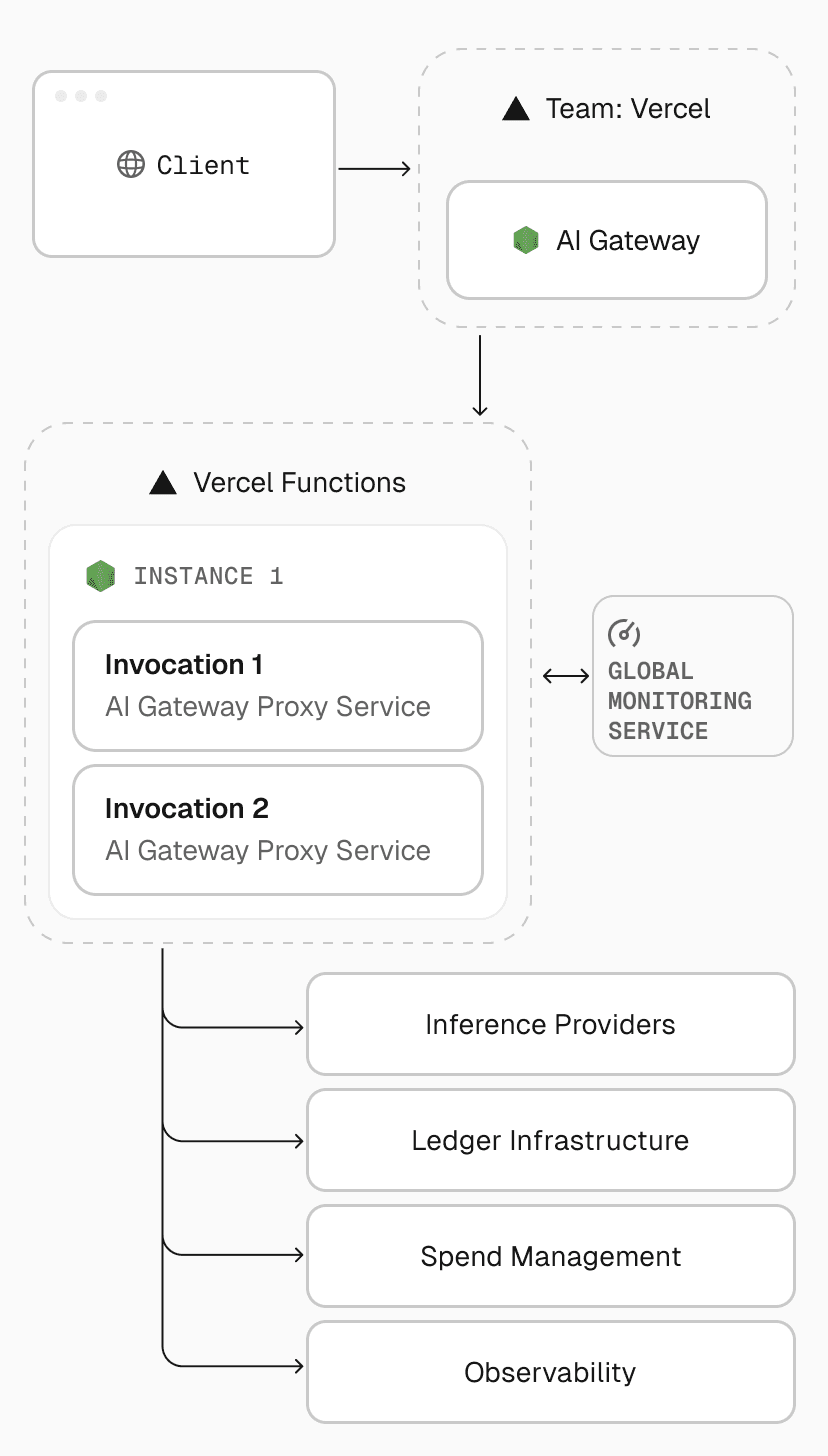
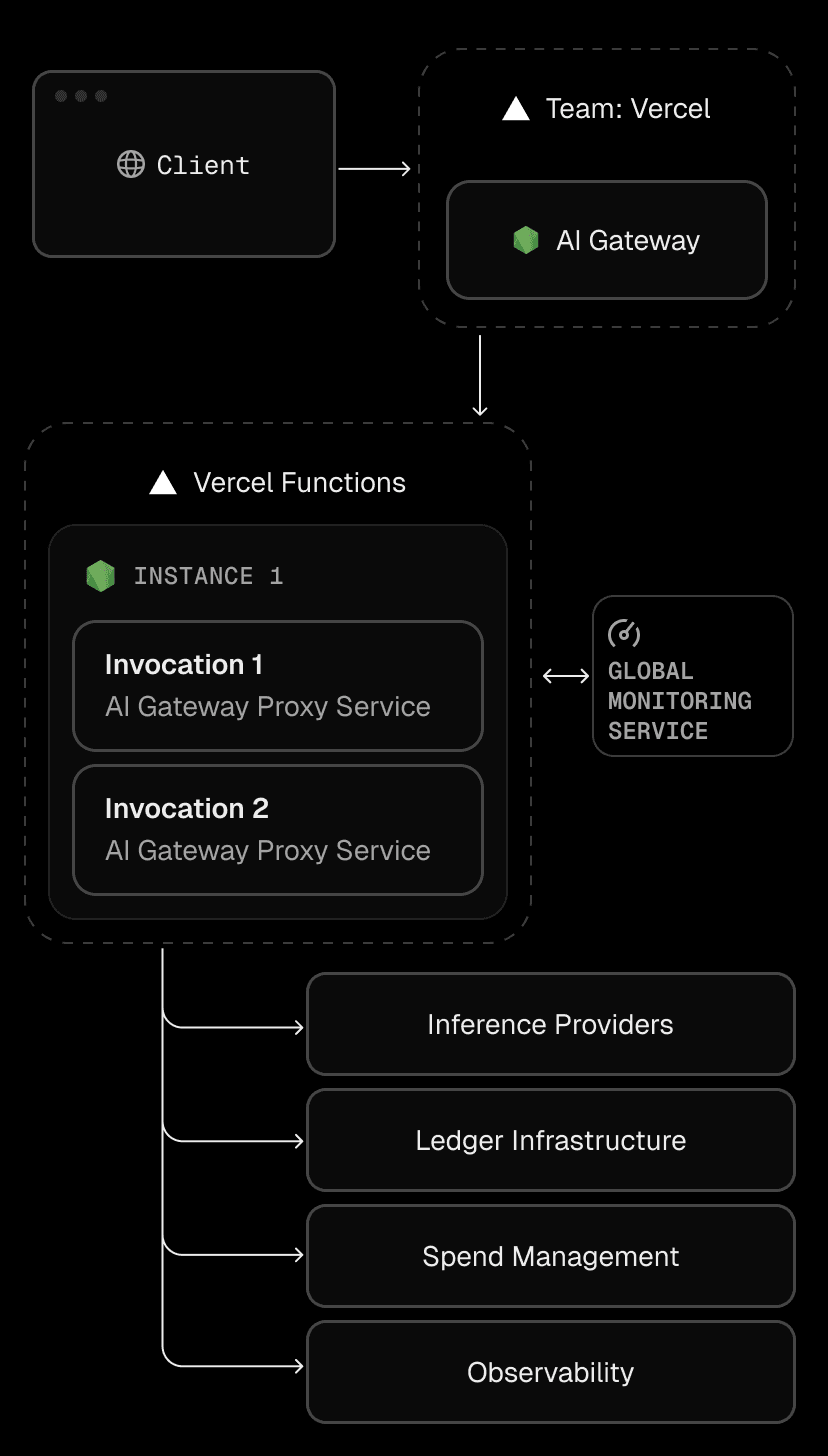
Because Fluid instances are reused, these instances can store small, short-lived caches of frequently accessed data such as provider routes, credentials, or quota snapshots directly in memory. This reduces redundant Redis lookups and minimizes latency on the hot path. When traffic spikes, Fluid scales instantly. When traffic quiets down, instances retire gracefully. Infrastructure stays elastic like serverless but performs like a tuned, always-warm server.
Link to headingState, caching, and global coordination
AI Gateway uses Redis, configured via the Vercel Marketplace, for global consistency and quota tracking, paired with Fluid for ephemeral in-memory caching for local speed. Frequently accessed credentials, provider metadata, and quota counters are stored in instance memory for sub-millisecond access.
We refresh values in Redis asynchronously in the background, minimizing impact to live traffic. Writes and usage increments are batched and written back to Redis after responses complete.
Each Vercel region maintains its own Redis cluster to keep quota verification and usage updates local. That regional isolation keeps latency predictable even at global scale.
Link to headingMonitoring from the inside out
Each Fluid instance continuously feeds the AI Gateway monitoring service with live metrics from two complementary systems: frequent health checks and in-memory statistics.
Health checks continuously measure core metrics like error rates, time to first token (TTFT), and throughput in tokens per second. In parallel, every Fluid instance maintains its own set of real-time counters tracking active invocations, memory utilization, and provider latency. These two sources create a self-correcting feedback loop. The monitoring system compares in-memory telemetry against global health checks and uses that data to adjust routing, scale instances, or shift traffic between regions automatically.
If one provider region starts returning slower responses, AI Gateway reroutes new requests to a healthier provider without human intervention or application changes. This system ensures reliability and resilience even as underlying model APIs fluctuate.
AI Gateway can route requests across multiple providers for the same model, and now, even fall back to other models in the event of an error, context size mismatch, or other incompatibility issue.
For example, Claude Sonnet 4 is available through Anthropic, Amazon Bedrock, and Google Vertex AI. You can control which providers are used and in what order:
import { streamText } from 'ai';
const result = streamText({ model: 'anthropic/claude-sonnet-4', prompt: 'Write a technical explanation', providerOptions: { gateway: { order: ['vertex', 'bedrock', 'anthropic'], }, },});If the primary provider is unavailable, AI Gateway automatically retries with the next one. Every response includes detailed metadata describing which provider served the request, any fallback attempts, latency, and total token cost. This fallback system improves reliability without requiring any changes to your application code.
Vercel provides native visibility into AI Gateway activity through Vercel Observability, giving developers detailed metrics on latency, provider health, token counts, and costs in real time.
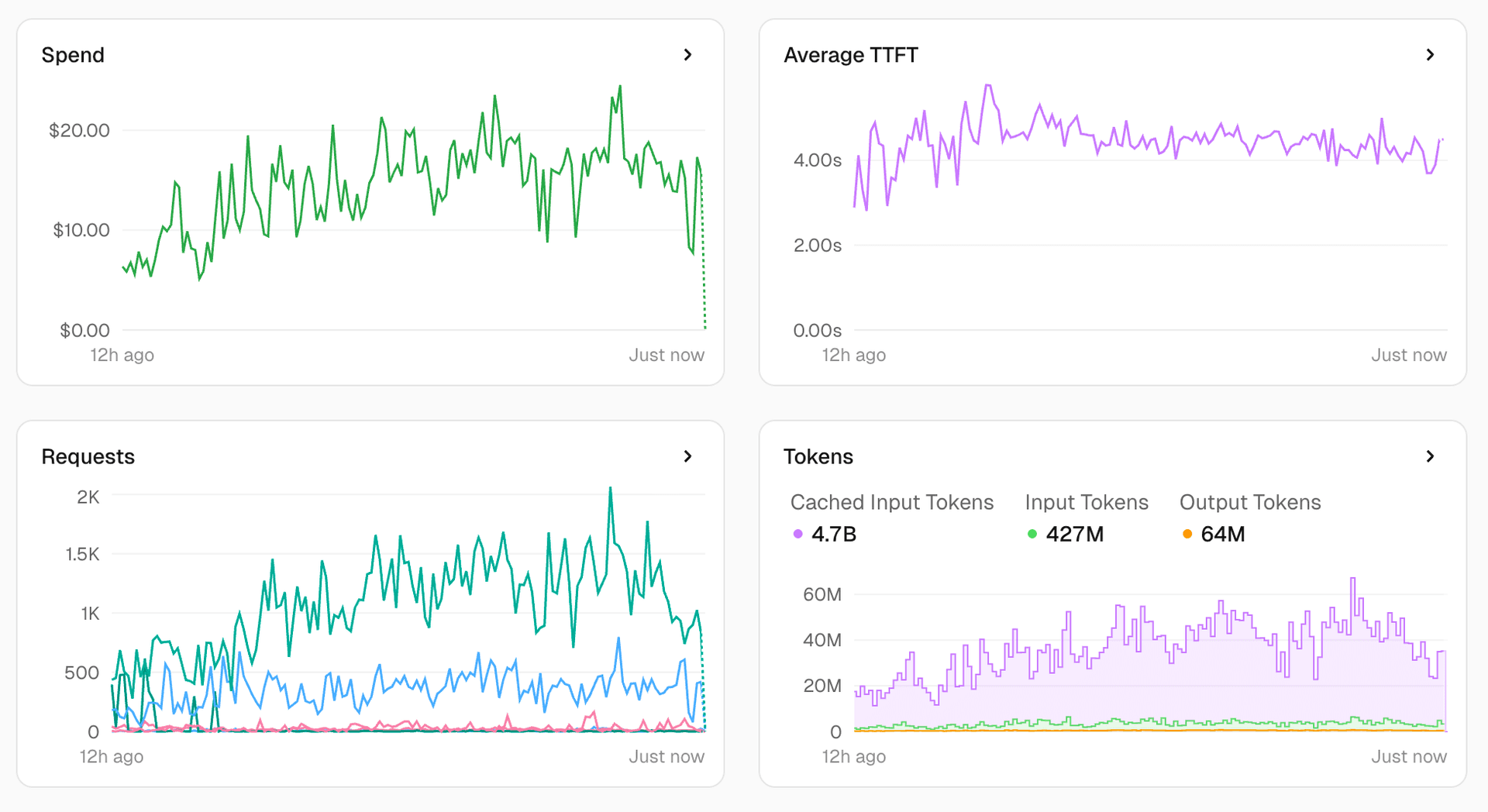
Link to headingWhy Fluid compute is the right fit
AI Gateway spends most of its time waiting, not computing. Routing requests, verifying credentials, and checking quotas takes milliseconds. Waiting for OpenAI or Anthropic to stream back a response takes seconds. This is a network-bound workload, not a compute-intensive one.
Active CPU Pricing matches the actual work pattern. During those seconds of waiting, you pay only for memory provisioning, not full CPU rates. For workloads like AI Gateway, where most time is spent waiting on network responses, this pricing model eliminates unnecessary costs.
Link to headingBuilding with Vercel
By using Fluid’s concurrency model and Vercel’s distributed network, AI Gateway demonstrates what modern infrastructure looks like when serverless evolves beyond simple functions. It's still instant and elastic, but now intelligent, efficient, and self-optimizing. The same architecture that powers AI Gateway is available to every developer building the next generation of AI-powered applications on Vercel.